이 장에서는 Cache Memory 에 대해 살펴보겠습니다.
컴퓨터 메모리 시스템들의 주요 특성
위치(Location)
-Internal : registers( 플립플롭으로 구성, 한 클럭만에 R/W. 굉장히 빠름),
cache memory(SRAM), main memory(DRAM)
-External : optical disks, magnetic disks, tapes
용량 (Capacity)
-Number of words : 내부 메모리 용량 단위
-Number of bytes : 외부 메모리 용량 단위
전송 단위(Unit of Transfer)
-Word
-Block
※word 란? 어느 프로세서의 데이터 버스의 단위,
ex) 32비트 프로세서면 데이터 버스의 폭이 32비트 하나의 word, 한꺼번에 전송 가능한 데이터 32비트
메모리 접근 방식(Access Method)
-Sequential : magnetic tape
-Direct : 하드디스크
-Random : SRAM, DRAM (주소만 주면 바로 접근)
-Associative : 데이터 내용에 따라 해당되는 주소을 알 수 있음
성능(Performanece)
-Access time
-Cycle time
-Transfer rate
물리적 구현 형태(Physical Type)
-Semiconductor: RAM
-Magnetic: Disk & Tape
-Optical : CD & DVD
-Magneto-optical
물리적 특성
-Volatile/nonvolatile
-Erasable/nonerasable
메모리의 조직(Organization)
-memory modules
이렇게 공부를 할겁니다. 차근차근 가보겠습니다.
컴퓨터 메모리 시스템들의 주요 특성
-위치
Internal memory 의 대표는 main memory 입니다. 특별히 레지스터는 내부 메모리라 안 하고 그냥 레지스터라고 부릅니다. Cache 는 SRAM 으로 구성되어 있어서 매우 빠른 레지스터와 상대적으로 느린 DRAM 으로 구성되어 있는 주기억 장치 사이에 존재합니다.
External memory는 하드디스크나 백업 장치 같이 외부 장치입니다.
-Capacity
word 나 block 단위
-전송 단위
internal memory의 전송 단위는 데이터 버스의 너비에 의존합니다. (word length,data bus width)
external memory는 대부분 word 큼
addressable unit 는 주소로 지정되는 방식
-접근 방식
Sequential access : 처음부터 시작해서 순서대로 값을 찾음 -> access time 은 현재 위치에 따라 정해짐 ex) tape
Direct access : hard disk, 특정 데이터가 특정 섹터의 특정 주소에 있음. ( 나중에 볼 겁니다.) 접근은 근처로 점프해서 Sequential 하게 찾습니다. head 의 위치에 따라 access time 이 달라집니다.
Random access : 해당 되는 데이터의 주소를 알고 있습니다. 주소만 알면 데이터를 찾을 수 있다는 말입니다.
Associative : cache , 내용에 따라 접근, 캐시의 구조를 보면 알 수 있습니다.
-성능
1. Access time(latency) : random access memory 에선 read/write 하는 시간 = 주소 값을 넣고 데이터를 얻는 시간
2. Memory Cycle time : access time + any additional time required before second access can commence
두번째 주소를 넣기 전에 안전화하는데 걸리는 시간 (전기적, 물리적 특성)
3. Transfer Rate(Bandwidth) 전송률
(1) random access memory 에선
Transfer rate = (1/cycle time)
(2) Non-random access memory 에선 (하드디스크)
TN = TA +(N/R)
TN : N 비트를 읽고 쓰거나 할때 필요한 시간
TA : average access time (데이터를 찾아가는 시간)
N : number of bits
R : transfer rate(bps), N/(TN - TA)
메모리는 계층 구조를 가집니다. (Memory Hierarachy)

윗쪽으로 갈수록 속도는 빠르고 용량이 작습니다. 또 비싸집니다. 아래로 내려가면 반대입니다.
물론 빠르고 좋은 걸 많이 쓰면 좋지만 비싸기 때문에 메모리 계층 구조 설계를 적절하게 조절해야합니다.
계층 구조
Registers
L1 Cache
L2 Cache
Main memory
Disk cache
Disk
Optical
Tape
메모리에 접근 참조(Reference)
지역성 (Locality)
Locality of Reference
지역성의 원칙은 최근에 쓴 데이터와 명령어를 다시 쓰는데에 초점이 있습니다. 두가지 지역성이 있는데요.
1. Temporal locality : 최근에 사용한 게 다음 번에 또 다시 사용될 거다.
2. Spatial locality : 어떤 데이터가 사용되면 그 주변 데이터가 쓰일거다.
ex) loop
sum = 0;
for(i = 0; i < n; i++)
sum += a[i];
return sum;공간적 지역성 : a[ ] array a[1]이 사용되면 a[2],a[3]와 같은 주변 배열이 다시 사용될 것이다.
시간적 지역성 : sum 이 계속 사용될 것이다.
참조의 지역성 특성을 이용해서 캐시가 탄생했습니다.
(많이 읽을 데이터를 가까이에 두자!)
Cache
-작고 빠름
-main memory 와 CPU 사이에 존재
위에 있던 계층 리스트를 보면
Registers
L1 Cache
L2 Cache
Main memory
이렇게 되어 있습니다. 보통 L1과 L2 밖에 없다면 L1은 레지스터, 즉 CPU 내부에 있고 L2는 Main memory 쪽에 있습니다. 만약 L3 까지 있다면 L1,L2 는 CPU 내부에 있고 L3 는 Main memory 쪽에 있습니다. (외부에 위치)


L1,L2 는 보이지 않고 L3 만 보이는 걸 볼 수 있습니다.

Hit 는 cache 에 CPU가 찾을려는 데이터가 있는 경우 입니다. 없으면 miss 입니다. Hit ratio는 Hit 한 비율이겠죠?
그래프는 그냥 Hit 가 많이 나면 access time 이 적다는 당연한 소리 입니다.
Cache operation - overview
이제 캐시의 동작에 대해 알아보도록 하겠습니다.
CPU가 특정 메모리에 있는 내용을 읽고자 할때 해당되는 메모리 주소를 발생을 시킵니다. CPU 입장에서는 느린 Main memory에서 가져오는 거 보단 캐시에서 가지고 오는게 좋습니다.
만약 캐시에 있다면 캐시에서 가지고 옵니다(빠름)
없다면 메인 메모리에서 가져옵니다.
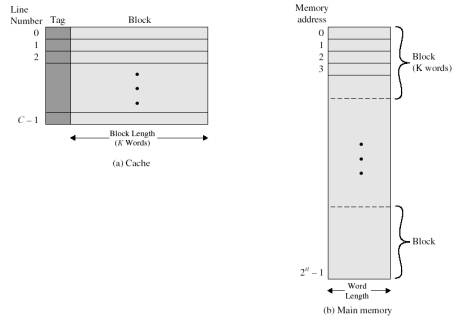
메인 메모리가 블럭 단위로 캐시에 저장됩니다. (한 칸이 아니라)
캐시 설계 고려
-크기
-Mapping Function (메인 메모리의 특정 데이터가 캐시 어디에 저장이 될 것이냐)
-Replacement Algorithm
-Write Policy
-Block Size
-Number of Caches
-크기
비싸고 빠름. 근데 너무 많으면 데이터를 찾는 하드웨어 로직부분에 딜레이가 많아지기 때문에 적당하게 필요
-cache addressing(캐시 주소지정)

프로세서는 진행되고 있는 프로그램입니다. 그리고 이 프로세서에서 돌아가는 데이터 주소와 메인 메모리에 저장되어있는 주소는 다릅니다. 즉 가상 주소(virtual address), physical address 를 변환 시켜주는게 MMU 입니다. 그 캐시 위치가 어디있냐가 이슈가 됩니다. 가상 주소를 받을지 물리적 주소를 받을지 말입니다.
장단점이 다 있습니다. 프로세서에 가까이 즉 Logical Cache를 이용할때는 Processor가 캐시에 직접적으로 접근합니다.MMU로 굳이 물리적 주소로 변환하지 않아도 됩니다. (Faster) 하지만 단점은 멀티 프로세서가 context switching 을 해서 다른 프로세서를 이용할때 상대적 주소이기 때문에 캐시가 싹 다 지워지고 새로 진행해야합니다.
메인 메모리에 가까운 형태로, 즉 물리적 주소를 받을 때는 즉 Physical Cache


1. 접근하고자 하는 데이터 주소를 내보냅니다. 캐시에 데이터가 있는지 확인합니다.
2. cache miss 가 일어나서 Main memory 에 데이터를 찾아옵니다.
3. 데이터를 프로세서에게 보내고 캐시에도 저장합니다.
Mapping Function
Main memory 의 용량보다 캐시의 용량이 작기 때문에 어떻게 저장이 될지 , 세가지 방식이 존재합니다.
1.Direct
2.Associative
3.Set Associative
먼저 Cache의 크기가 64k Byte 그리고 Cache block 이 4 bytes 라고 합시다.
64 k = 2^3 x 2^2 x 2^10 = 2^16
전체가 64k입니다. 그리고 블록 사이즈가 4 bytes = 2^2 이기 때문에 2^16 / 2^2 = 2^14 개의 라인 개수를 가진다는 것을 알 수 있습니다.
메인메모리는 16MBytes 입니다. 2^2 x 2^2 x 2^20 = 2^24 입니다. address는 24bit 입니다.
▷Direct Mapping
직접 매핑입니다. 매핑이 뭐냐면 메인메모리의 데이터가 캐시로 저장될 때 입니다. 그럼 어떻게 저장하냐?
Direct Mapping은 다음과 같습니다.

m은 캐시의 라인 개수 입니다. j는 메인 메모리 주소입니다. i는 캐시 라인의 인덱스 입니다.
만약 메인 메모리에서 주소 12인 데이터가 캐시에 저장될때 이 캐시의 라인이 8개면 12 mod 8 = 4, 4번째 에 저장이 된다는 의미입니다. 20은 20 mod 8 = 4 , 아 같은게 들어가네요. 그러면 앞에 있었던 걸 대체해야겠죠.
그럼 여기선 4, 12, 20, 28 은 다 같은 4번째에 들어가겠습니다. 만약 실제로 4,12,20,28을 차례대로 읽어야 한다고 생각을 해봅시다. 끔찍하게도 캐시 miss가 왕창 나기 때문에 계속 main memory로 접근을 해야만 합니다.

특징
-각 메인 메모리의 블록은 오직 하나의 cache line에 들어갈 수 있다.
-주소에서 하위 w bits는 word를 구별하는데 사용이 된다.
-주소에서 상위 s bits는 block 을 구분하는데 사용이 된다.
| Tag s-r 8 |
Line or Slot r 14 |
Word w 2 |
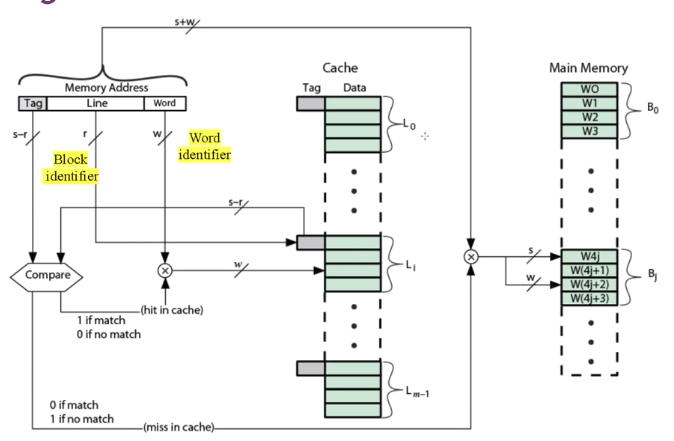
그전엔 그냥 Main Memory를 하나에 블럭으로 표현했는데 여기서는 W0, W1, W2, W3 로 나눠져 있습니다. 4개를 구분해야하니깐 비트는 2비트가 필요합니다.
| Tag s-r 8 |
Line or Slot r 14 |
Word w 2 |
Word는 블럭내에서 구분을 해주고 Tag는 그 값이 그 곳에 존재하냐를 구분해줍니다. 이게 뭔 소리인가 싶지만 위에서 같은 라인에 들어가는 4,12,20,28 을 구분해주는 겁니다. 4가 캐시안에 들어가있습니다. 저희는 20을 찾고 싶습니다. 일단은 캐시에 가서 4번째 캐시에 데이터가 들어있는지 확인 하겠죠. 근데 이게 20인지 4인지 12인지 28인지는 태그를 보고 확인할 수 있다는 말입니다.
라인 비트가 14 bits 죠. 왜냐면 앞에서 우리가 계산했듯이 캐시의 라인이 2^14 이기 때문입니다.
장단점
장점 : Simple, Inexpensive
단점 : 쉽게 찾을 수 있지만 캐시에 저장될 수 있는 위치가 고정되어 있기 때문에 비효율적 (다른 곳은 비어있기 때문에)
=accesses 2 blocks same line repeatedly -> cache misses are very high
Victim Cache
이는 Direct Mapping 방법이 너무 비효율적이라 작은 캐시를 만든 겁니다. 같은 라인을 접근할때 바로 메인메모리로 들어가는게 아니라 이 캐시 안에 들어갑니다. Direct Mapping 방식의 단점을 극복하기 위한 캐시입니다.

▷Associative Mapping
Direct Mapping 방식을 해결하기 위한 극단적인 방식입니다.

메인메모리 한 블럭이 가리키는 화살표를 잘 봅시다. 이건 캐시 어디든지 저장이 가능하다는 소리입니다.(Direct Mapping 과 정반대입니다)
그럼 어떻게 구분하냐? 다 태그와 워드로 구분합니다.
메인 메모리의 주소를 태그에 집어 넣어라는 말과 동일합니다.(그래야 구분이 가능합니다.)

보면 태그가 큽니다. 그리고 모든 태그를 가지고 와서 Memory Address의 태그와 비교합니다. (Direct Mapping 에서는 넣을려는 위치의 태그와 한번만 비교했으면 됐었습니다.)

장점은 캐시 활용도를 높힐 수 있고 단점은 태그를 모두 비교해야하기 때문에 overhead가 발생할 수 있습니다.
(Address 에서 word수 만큼 >> 해주어야합니다. )
| Tag 22bit | Word 2 bit |
Line Number 의 개념은 중요하지 않습니다. 태그에 주소 그자체가 들어가기 때문입니다.
장점은 flexible 한다는 거고 단점은 비교할때 너무 많은 계산을 한다는 겁니다.
▷Set Associative Mapping
Direct 와 associative mapping 의 특성을 잘 활용한 형태입니다.
캐시가 셋(set)으로 나누어 집니다 .
그 셋은 라인(line)을 포함합니다. 그리고 그 라인에 따라 자유롭게 들어갈 수 있습니다.
set 이 정해지면 way가 있는겁니다.
보통 2way , 4way 가 일반적입니다.
ex) line - 16 , v = 8set-> k= 2 lines/set, 2way

표시된 숫자들이 셋에 들어갈 수 있는 숫자들이고 색깔이 있는 숫자들이 현재 셋에 들어있다는 걸 의미합니다. 2 way 니깐 숫자 2개씩 들어갈 수 있습니다.

그림을 얼핏봐도 Direct Mapping 과 Associative Mapping 이 혼합된 걸 느낄 수 있습니다.

1. Set 보기
2. 그 Set 에 K의 자유도
3. 해당되는 set에 태그를 모두 비교
4. 있으면 hit 없으면 miss
Associative Mapping의 모든 태그를 비교하는 방식보다 훨씬 효율적입니다.
| Tag 9 bit | Set 13 bit | Word 2bit |
Word 가 2비트니깐 구분 해야하는게 2^2 = 4개 임을 알 수 있습니다. 만약 바이트단위라면 4bytes 즉 하나의 블록 크기 가 32bit 인걸 알 수 있습니다.

set이 339C 인데 word 가 포함된 값이기 때문에 >> 2를 해주면 0CE7이 나옵니다. 그래서 동일한 Set Number에 들어간 것을 알 수 있죠. 만약 태그가 1FF인 블록에 set이 339C 인 데이터를 캐시에 넣는다면 자유도가 2-Way니깐 오른쪽 set에 들어갈 겁니다. (만약 자리가 없으면 덮어쓰여집니다.)
way 가 1뿐이면 Direct mapping 입니다.
set하나고 k가 n개 라면 Associate mapping 입니다.
Replacement Algorithms
Direct 냐 Associative 냐 Set Associative Mapping 이냐에 따라서 Replacement 알고리즘이 달라집니다.
1. Direct Mapping Replacemnet Algorithms
simple 한 Direct Mapping 에서 메인메모리의 데이터가 갈 수 있는 장소는 한 곳입니다. 만약 동일 장소에 다른 데이터를 읽고 싶으면 기존의 데이터가 반드시 쫓겨나게 됩니다.
No choice -> Each block only maps to one line -> Replace that line
2. Associaitve & Set Associative
여유가 있는 만큼 넣을 수 있으나 꽉 차있으면 대체 해야합니다. 어느 데이터를 내보낼지 네개의 방식이 있습니다.
1) Least Recently used(LRU)
- 최근에 안 사용된거
2) First in first out(FIFO)
- 가장 오래된 거 (Queue)
3) Least frequently used
- 자주 사용되지 않은거 ( hit 가 가장 적게 난거)
4) Random
Write Policy
두가지 Write 방식이 있습니다.
1. Write through 2. Write back
프로세서가 메모리에 액세스합니다. 그러면 이 메모리에 내용이 캐시에 없다면 캐시 미스가 일어나고 캐시에 저장이 됩니다. 그러고 프로세스가 메모리에 값을 변화합니다.(+1 같은) 그러면 캐시 값이 변하겠죠? 이와 동시에 메인 메모리의 값도 변화하는 것을 'Write Through' 라고 합니다.
이와 다르게 Write back 은 캐시에서 값이 쫓겨날때 메인메모리에 업데이트가 되는 겁니다. 그럼 동작을 하는 동안에는 캐시와 메인 메모리에 값 불일치가 일어납니다 . 캐시에서 그 값이 쫓겨나는 순간 업데이트가 되는 겁니다.
Write through 방식은 매번 업데이트를 해줘야하기 때문에 트래픽이 일어나기 쉽고 Write back은 메인메모리와 캐시의 값이 불일치 하기 때문에 복잡한 로직이 필요합니다. 한 코어에 여러 프로세서를 쓴다고 하면 안에 메모리도 여러개일텐데 어떻게 될지 생각해볼 수 있습니다.
United Cache - 명령어와 데이터가 동일한 캐시
Splited Cache - 명령어와 데이터가 분리된 캐시
요새는 Splited Cache 를 많이 씁니다.
※L2 캐시가 L1 보다 커야 성능향상에 좋습니다.
Cache Memory 에 대해 배우는 Chpater 4가 끝났습니다.
메모리의 구조, Cache memory의 원리와 디자인 특히 Mapping function 에 대해 자세히 알아보았습니다. 수고하셨습니다.
'공부 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터구조6 External Memory (0) | 2020.06.13 |
|---|---|
| 컴퓨터구조5 Internal Memory (0) | 2020.06.12 |
| 컴퓨터구조3 CPU (0) | 2020.05.29 |
| 컴퓨터구조2 Process (0) | 2020.05.27 |
| 컴퓨터 구조1 개요 (0) | 2020.05.26 |



